
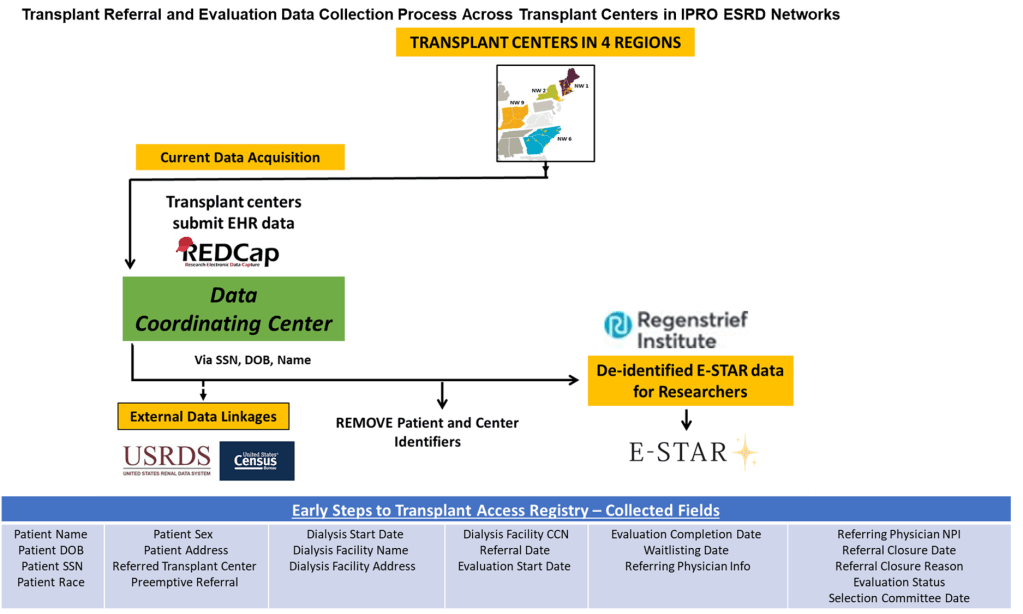
Step 1: Transplant centers submit their identifiable data to IPRO via a REDCap platform.
Step 2: IPRO examines the data and conducts additional quality checks for missing values, field validation errors, and incorrect values. IPRO reaches out to Tx centers with large amounts of missing or incorrect values and asks for recollection to ensure completeness.
Step 3: IPRO uses EQRS, a national data collection system for Medicare-certified dialysis facilities and uploads administrative and clinical data to the CMS in real-time, to backfill missing dialysis facility fields (i.e., dialysis facility’s CCN) and create a unique patient- and transplant center-specific IDs.
Step 4: An identifiable finder file is sent via Secure File Transfer Protocol to the USRDS to link with USRDS-generated patient IDs. This linkage is important to identify ESKD-population denominator data for analyses.
Step 5: IPRO links the merged file via UNOS center ID to an SRTR data file containing publicly available Tx center characteristics for all US transplant centers.
Step 6: All patient and transplant center identifiers are replaced with IPRO-generated patient and transplant center unique IDs before sending merged dataset to the Regenstrief Institute.
Step 7: The Regenstrief Institute links this merged patient- and transplant center- de-identified file via USRDS patient ID to a USRDS-supplied file of denominator (all incident ESRD patients) data. The final limited E-STAR dataset includes linked USRDS denominator data and select SRTR transplant center data.
